大家好!我是Wayne。今天,跟大家分享6款非常實用的AI工具,全部開源免費,並且都能在本地電腦上運行。現在,使用AI工具來解決一些在工作、學習、生活中遇到的問題,已經成為了一種趨勢。
第一個:SadTalker。只需要一張照片,再加上一段語音,就能生成口型一致的影片。它是目前音訊驅動口型AI工具中效果比較好的一個。可以到這個網址手動下載安裝。如果直接使用整合包,解壓以後按兩下一鍵啟動,然後瀏覽器裡輸入本地網址就能使用。點擊上傳一張照片,照片不需要太大,但面部一定要清晰,不能有遮擋,特別是嘴巴部分,不能張嘴和露出牙齒。再上傳一段語音,然後設置右側的幾項參數。第一個參數是設置面部動作數量,包括眨眼、視線移動、頭部動作等等。預設是0,有程式自動控制。如果手動設置,推薦1-3,不要設置太多。第二個參數是選擇人臉分析模型,256和512指的是解析度,照片小就用256。第三項參數是生成影片的處理方式。第一個“crop”是裁剪,有程式自動控制剪掉照片的多餘部分,生成的影片是上半身。如果想要生成和照片同樣大小的影片,可以選擇第三個“full”模式。這裡要注意,使用這種處理方式,需要和下面的參數配合。
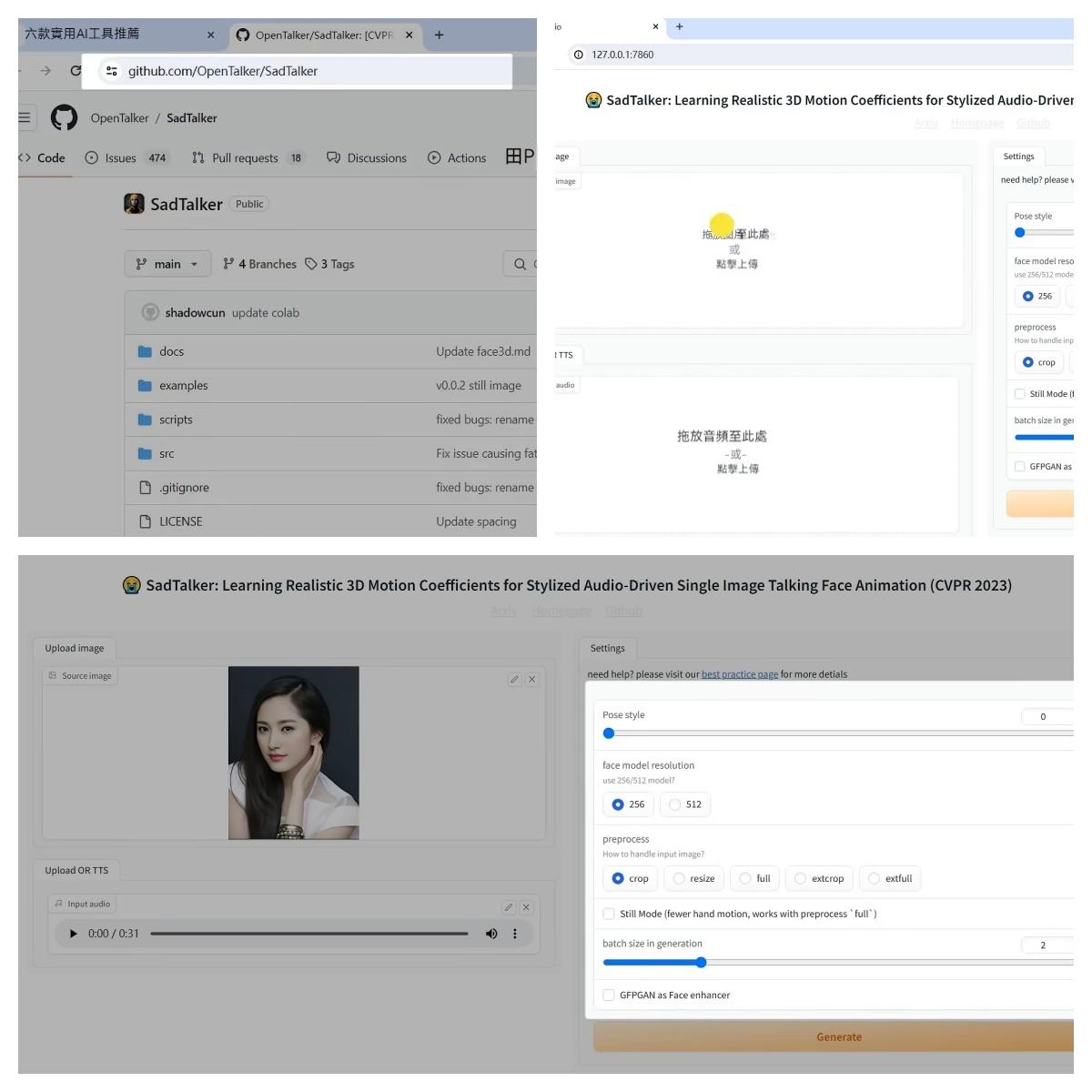
使用still mode一定要勾選,剩餘幾種方式效果不是太好,不常用。第五個參數跟顯示卡記憶體有關,提高生成影片的速度,可以根據顯示卡記憶體來調整,建議不要超過顯示卡記憶體的大小。最後是人臉高清選項,勾選以後,生成影片比較慢,但更加清晰。參數設好以後,點擊生成。我這裡大概用了十幾分鐘生成完成。可以把生成好的影片稍作剪輯,來看一下效果。如果用全身照來生成影片,想要不被裁剪,可以在右側參數這裡選擇第三種模式,並選上still mode。這樣生成的影片就會和圖片同樣大小,並且不會變形。
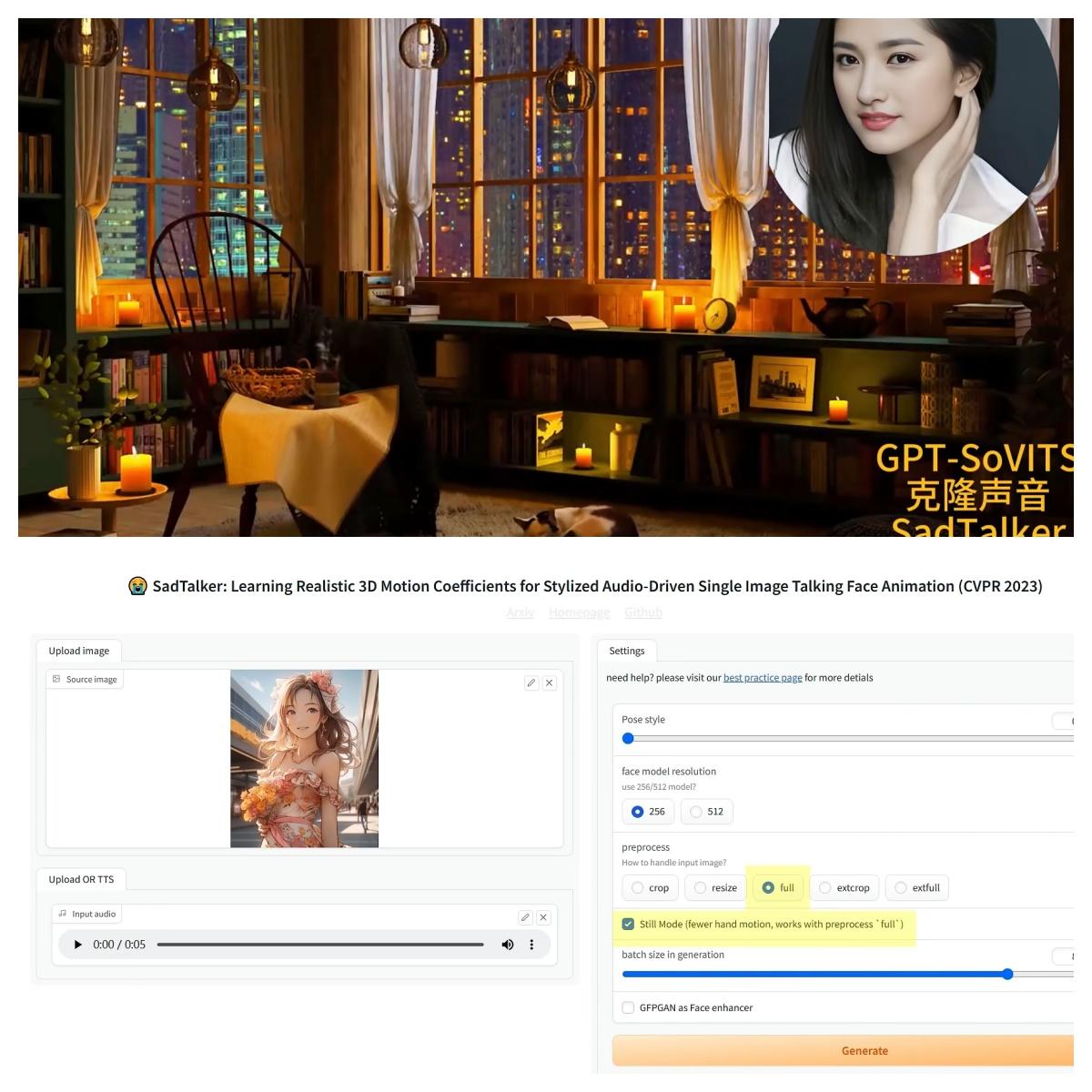
第二個:nougat。這款AI由Meta開源,功能比較小眾,但卻十分強大,而且目前僅此一款。它能把PDF的內容提取出來,自動轉成markdown語法,特別是複雜的數學公式以及表格的提取,對於搞學術研究的朋友來說,是一個非常實用的工具。按兩下整合包裡的一鍵啟動,然後網頁裡輸入本地網址就能使用,操作也非常簡單。點擊這裡上傳一個PDF,比如這份文檔,我想把第5頁提取出來,保存為markdown格式。轉換頁碼這裡輸入5,點擊提交。可以看到,內容和數學公式都成功提取了。我們在資料夾裡面可以找到相應的markdown檔,內容都用markdown語法重新做了描述,並且符合LaTeX排版系統的要求。它也保存了一個臨時的網頁檔,在這個static目錄裡。如果是多次提取,建議把這個網頁重新命名保存,這樣就不會被下一次提取的頁面覆蓋掉。
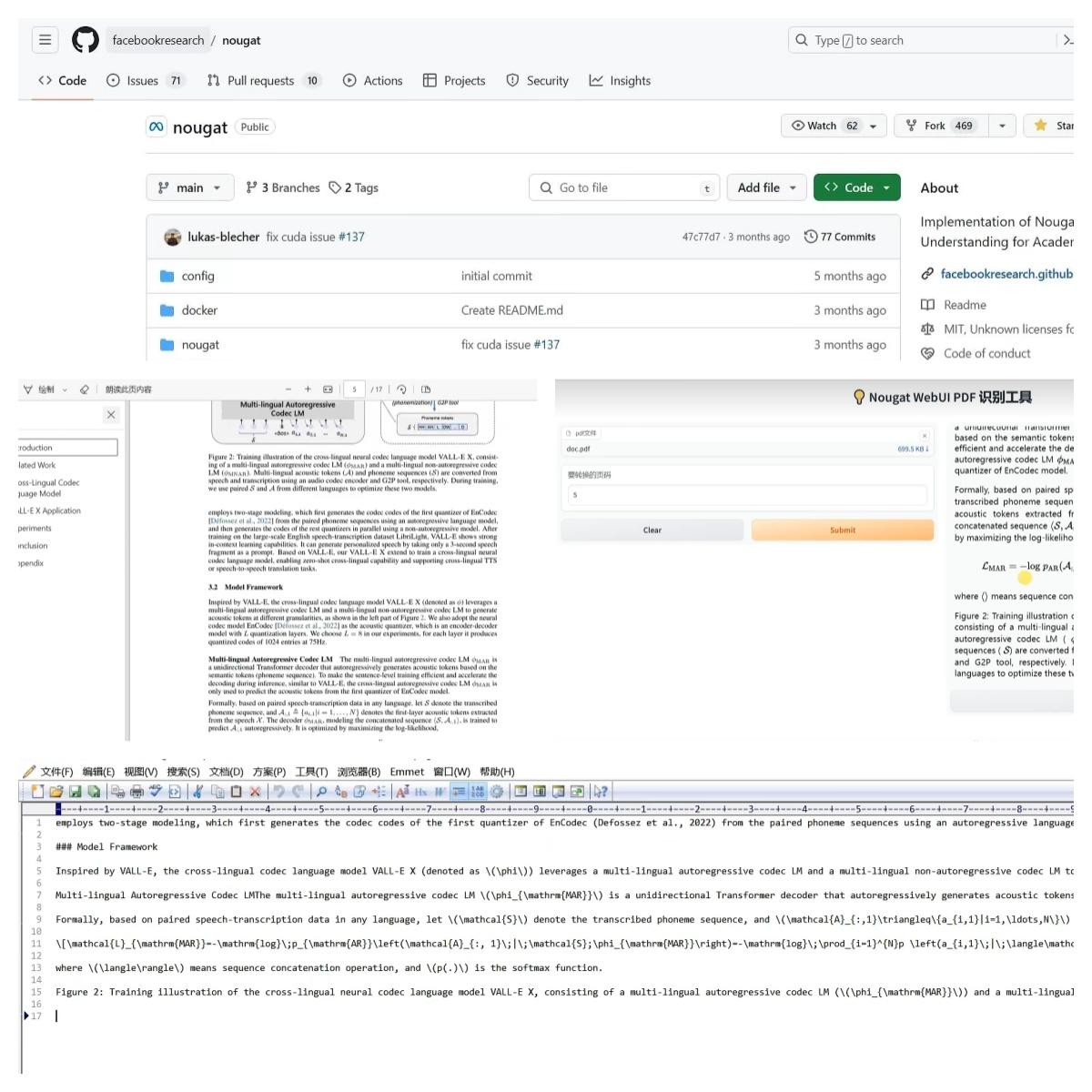
第三個.另一款PDF工具:stirling-PDF。雖然這款工具沒有用到AI技術,但功能卻十分全面。所有對PDF檔的操作,像合併、拆分、內容轉換等等,只要你想到的編輯功能,它都有。我們可以在它的官網直接下載。運行程式,點擊這裡進入最新的發佈列表,拉到底部。Windows系統有兩個運行檔可以選擇,功能都是一樣的。第一個多了登錄功能,第二個不需要登錄,打開就是操作介面。下載好以後,建議大家新建一個目錄,然後把這個運行檔放進來,可以創建一個快捷方式來運行。第一次運行時,它會自動下載一個Java虛擬機器,因為它是Java編寫的,依賴JDK環境才能運行。下載好以後,按兩下這個安裝包,所有選項都用預設。安裝好以後,JDK安裝包可以刪掉了。運行成功後,就自動打開網頁操作介面了,預設是英文的,點擊右上角可以切換成中文。
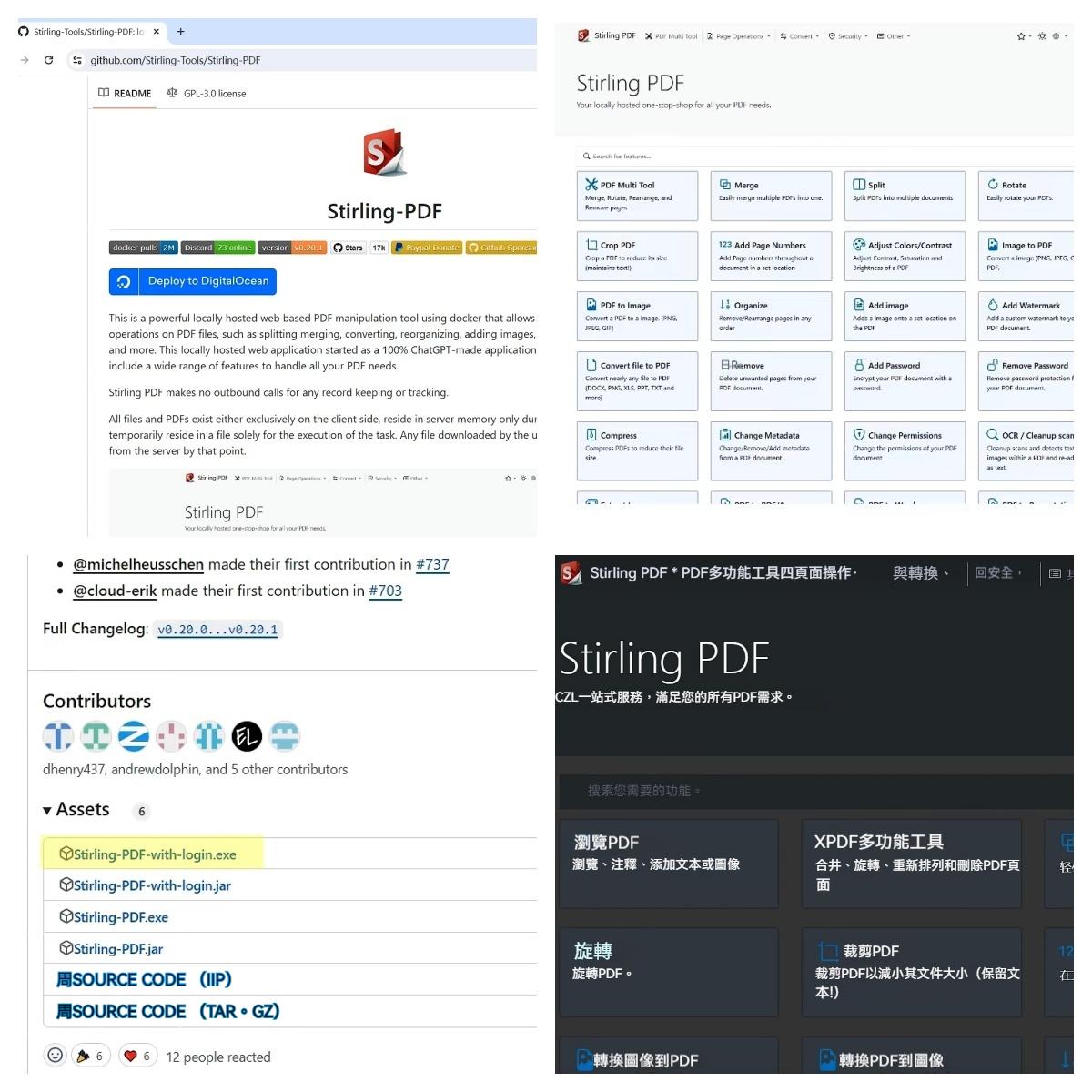
它的功能主要分為四大類。第一類是頁面操作,主要跟PDF文檔編輯相關,包括合併、拆分、刪除、裁剪等等。然後是格式轉換,包含了轉圖片、轉Excel,不過它並沒有上一款NOUGAT的功能。第三類是加密、加浮水印等跟安全相關的功能。最後是一些雜項功能,總共加起來差不多有40多種PDF操作。像一鍵提取圖片、PDF加密,這些功能都非常實用。NOUGAT再加上這一款PDF工具,基本上可以滿足對PDF操作的所有需求,並且它們都是可以在本地運行的,不用擔心資料隱私和安全問題。
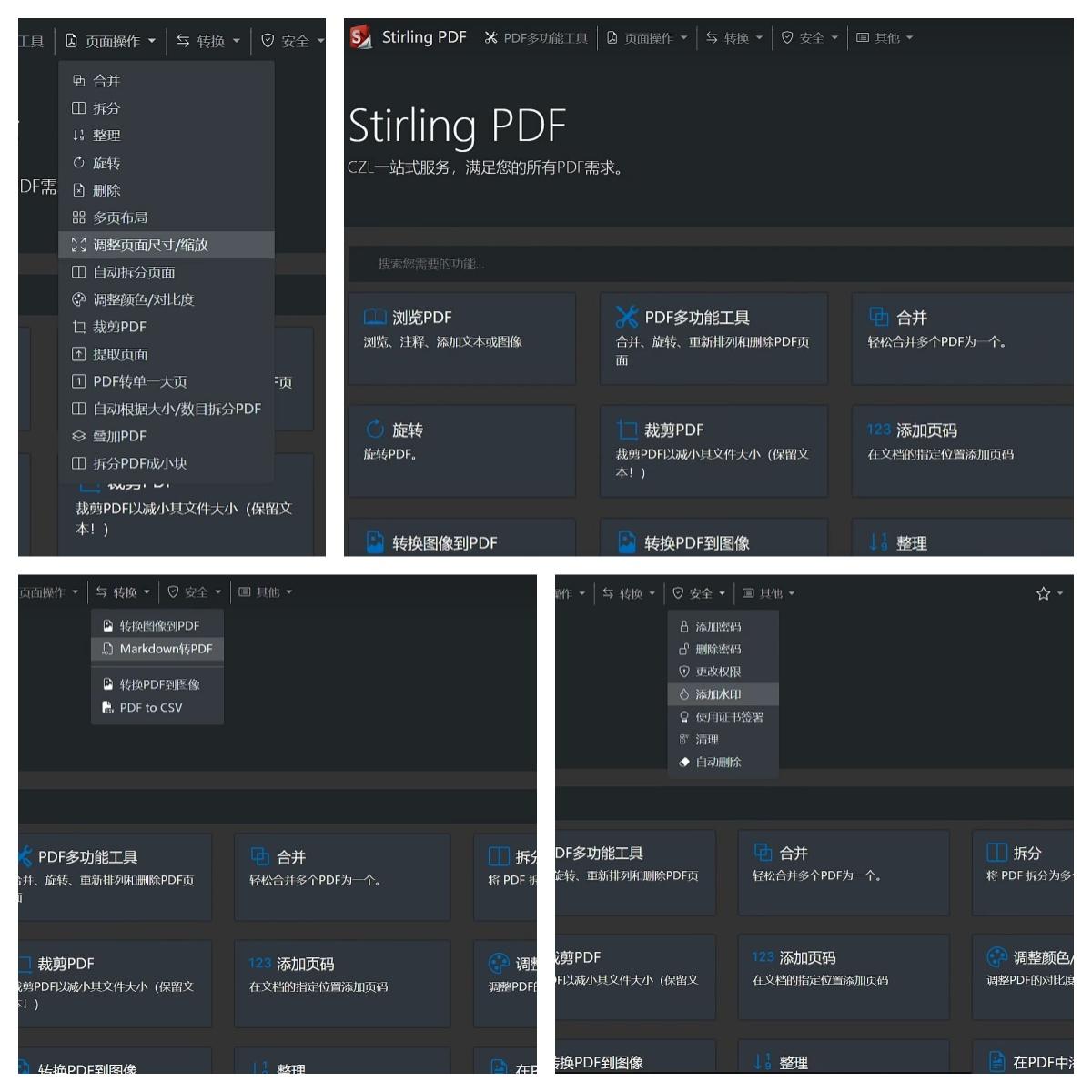
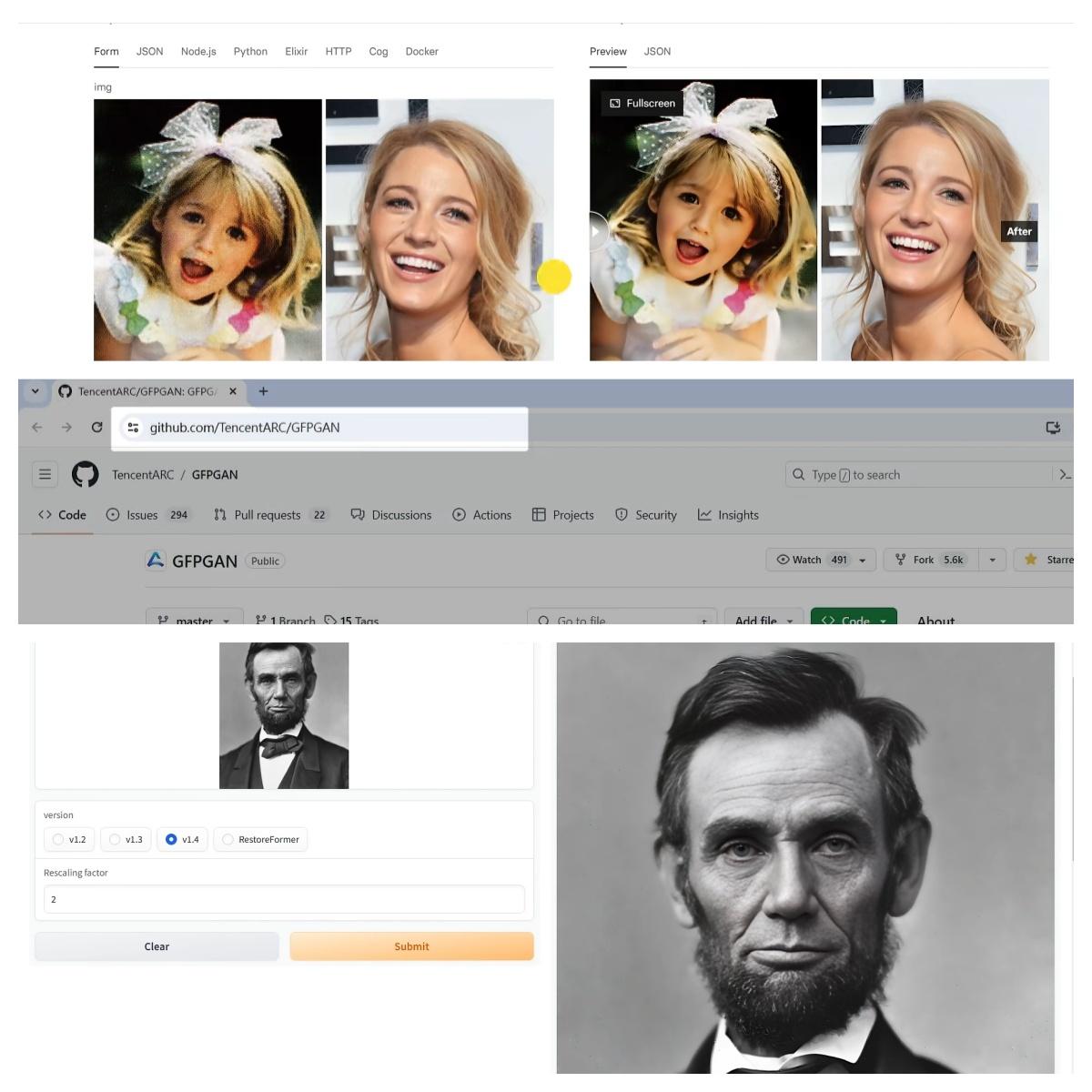
第四個:GFPGAN。在一些AI繪畫工具,比如SD ComfyUI,還有一些換臉軟件中,經常會看到這個名字。它能夠對各類人臉照片進行高清處理,特別是老照片的修復。雖然是2年前的技術了,但在這個領域,目前並沒有更好的工具能超越它。可以在這個網址下載安裝,它是能夠單獨運行的,也可以直接使用整合包,按兩下一鍵啟動,然後輸入本地網址就可以使用了。操作介面沒有複雜的設置,只需要上傳一張照片,模型就用預設的最新版1.4。下面的參數是設置照片的放大倍數,點擊提交按鈕,稍等片刻就處理完成了。對於老照片,特別是臉部區域比較模糊的,修復的效果是非常優秀的。
第五個. Faster-Whisper,它是基於open ai開源的Whisper語音模型和Facebook第二代翻譯模型開發的一款語音轉錄工具,能夠在更低配置的顯卡下實現語音的轉錄和翻譯。同樣,我也製作好了整合包,按兩下一鍵啟動就可以使用。它的功能介面主要分為四塊,分別是影片語音轉錄、線上提取(Youtobe上的影片字幕直接提取)、本地錄音以及多語言翻譯。
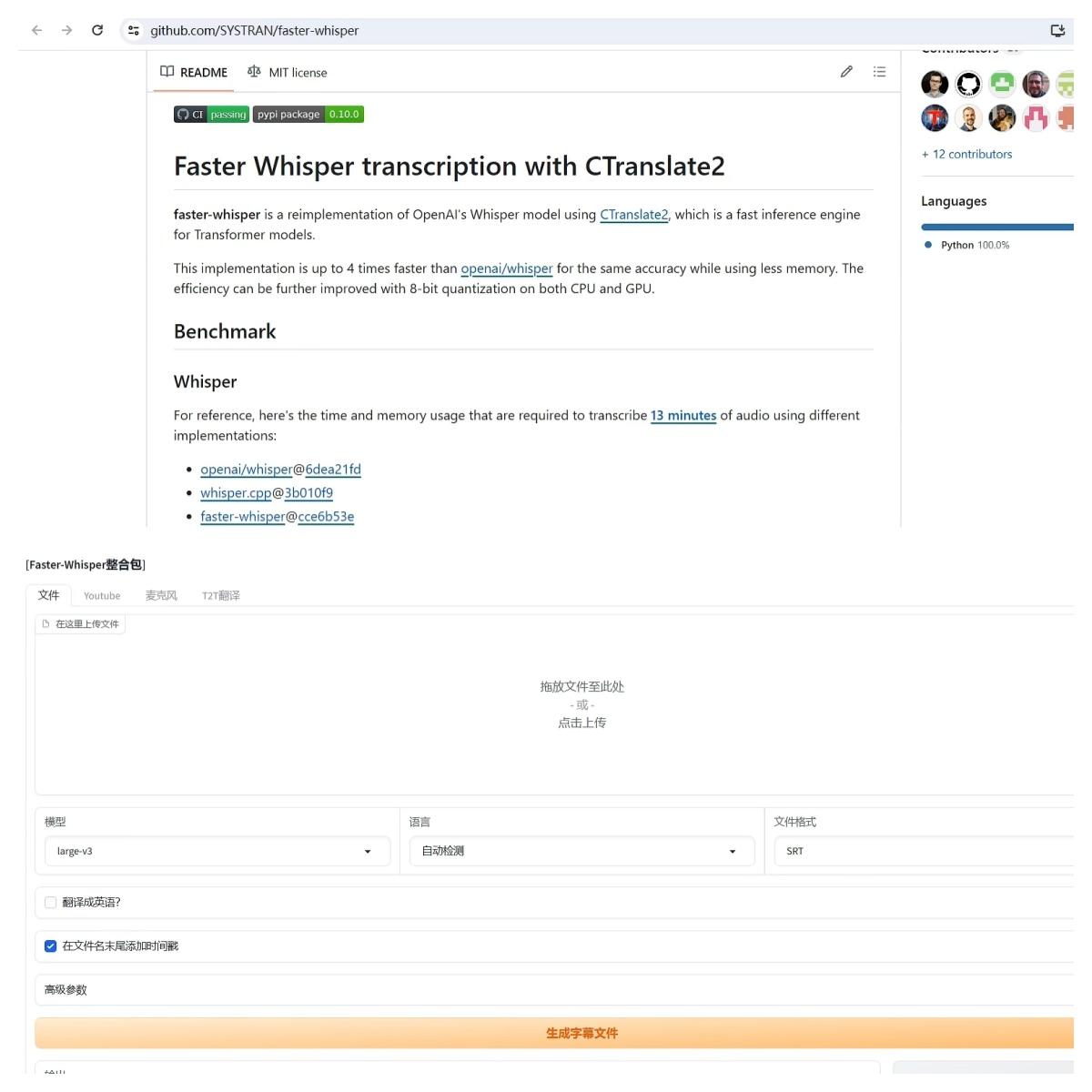
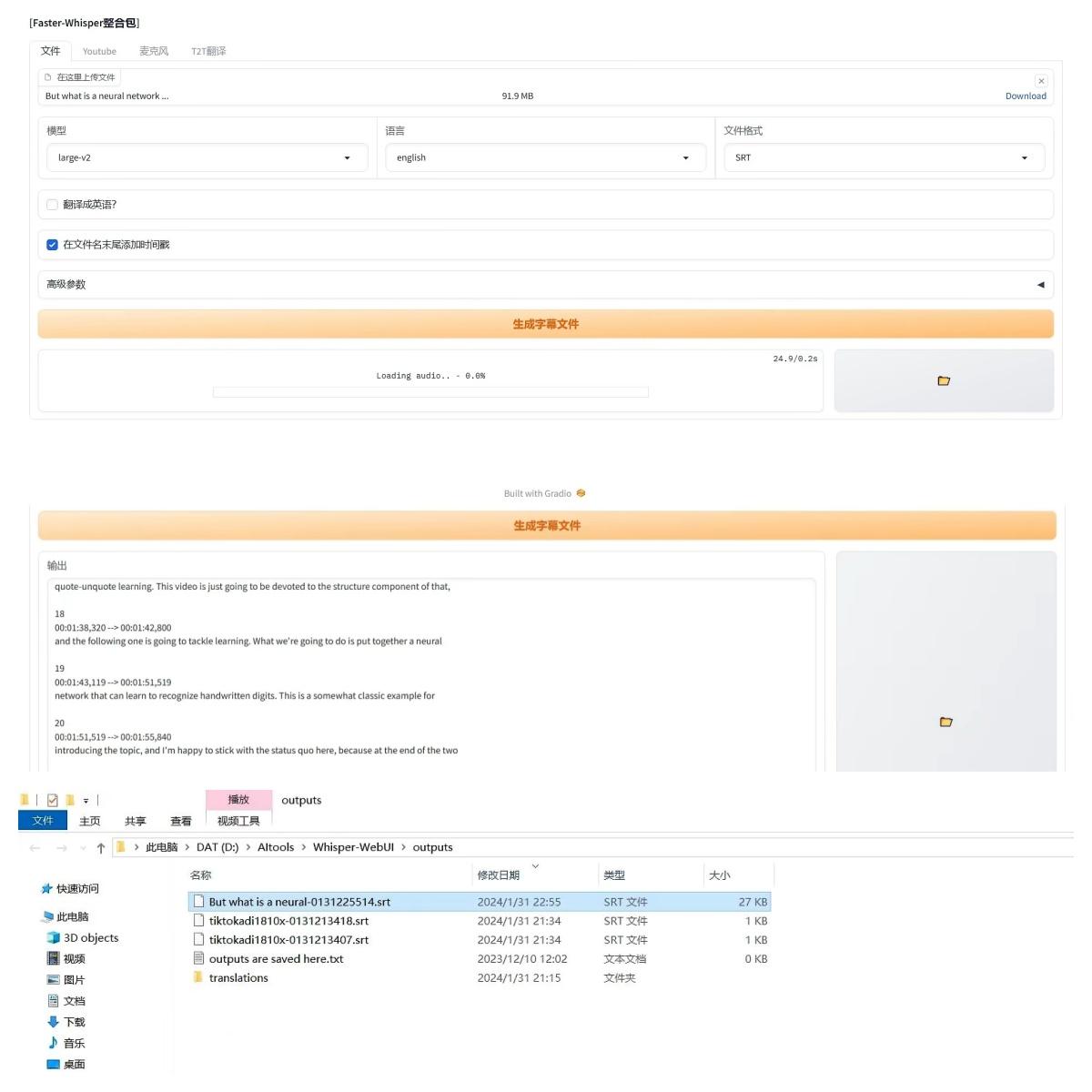
先來看第一個功能。點擊這裡,選擇一個影片檔,然後選擇模型。模型這裡要注意,如果沒有16G顯示卡記憶體,就選這個V2模型,不然會爆顯示卡記憶體。語言這裡建議不要使用自動檢測,改成影片裡使用的對應語言。檔案格式預設是字幕檔,可以選網頁文本和純文字。然後是下面的高級參數,前三項一般都默認。最後一個可以根據硬體設定選擇模型精度,配置低的可以選擇INT8,有8G以上顯示卡記憶體就用FLOAT16。然後點擊生成按鈕。這個影片大概半小時,提取時間大約要4分鐘左右。提取完成,生成的內容是標準的字幕格式,並且帶有時間戳記。點擊右側按鈕,定位到輸出資料夾,可以看到保存好的字幕檔。
第二個功能:線上提取Youtobe上的影片字幕。這裡輸入影片的分享網址,稍等片刻,就會載入出該影片的封面和標題。然後選擇下面的模型,同樣是用VR,再更改語言。是否翻譯為英語?如果勾選,速度會比較慢,這裡我就先不選了。然後點擊生成。因為要線上載入影片裡的語音,開始會比較慢。我這個影片總時長大概16分鐘,提取差不多要5分鐘左右。提取完成,這個就是我上期節目的字幕內容。同樣,在輸出目錄下也有對應的字幕檔。再來看一下第三個功能。點擊開啟本地麥克風,直接錄音。錄好以後點擊停止。下面的模型和語言選擇跟前面操作一樣,再把翻譯選項勾上,速度非常快,幾乎是同聲翻譯的效果。
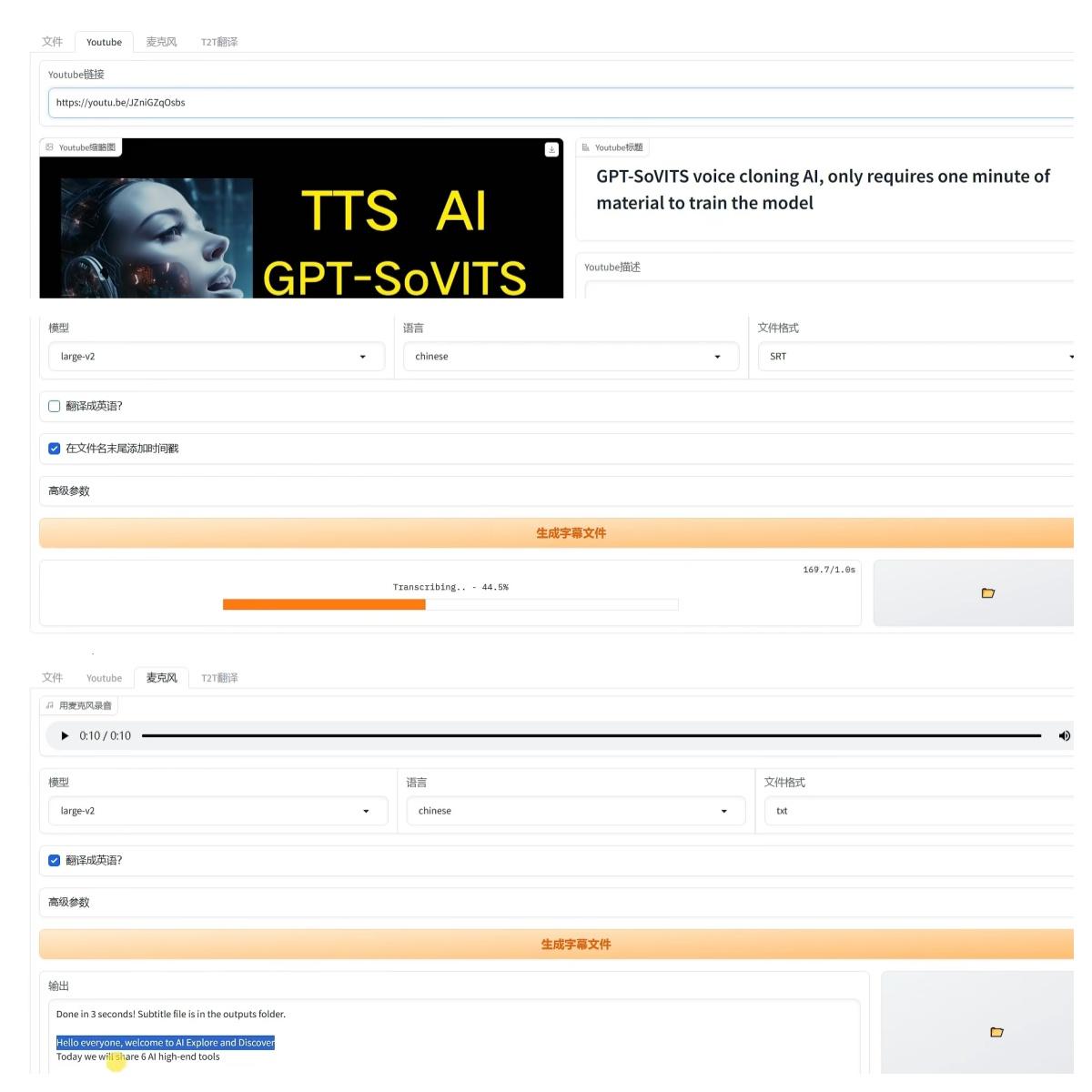
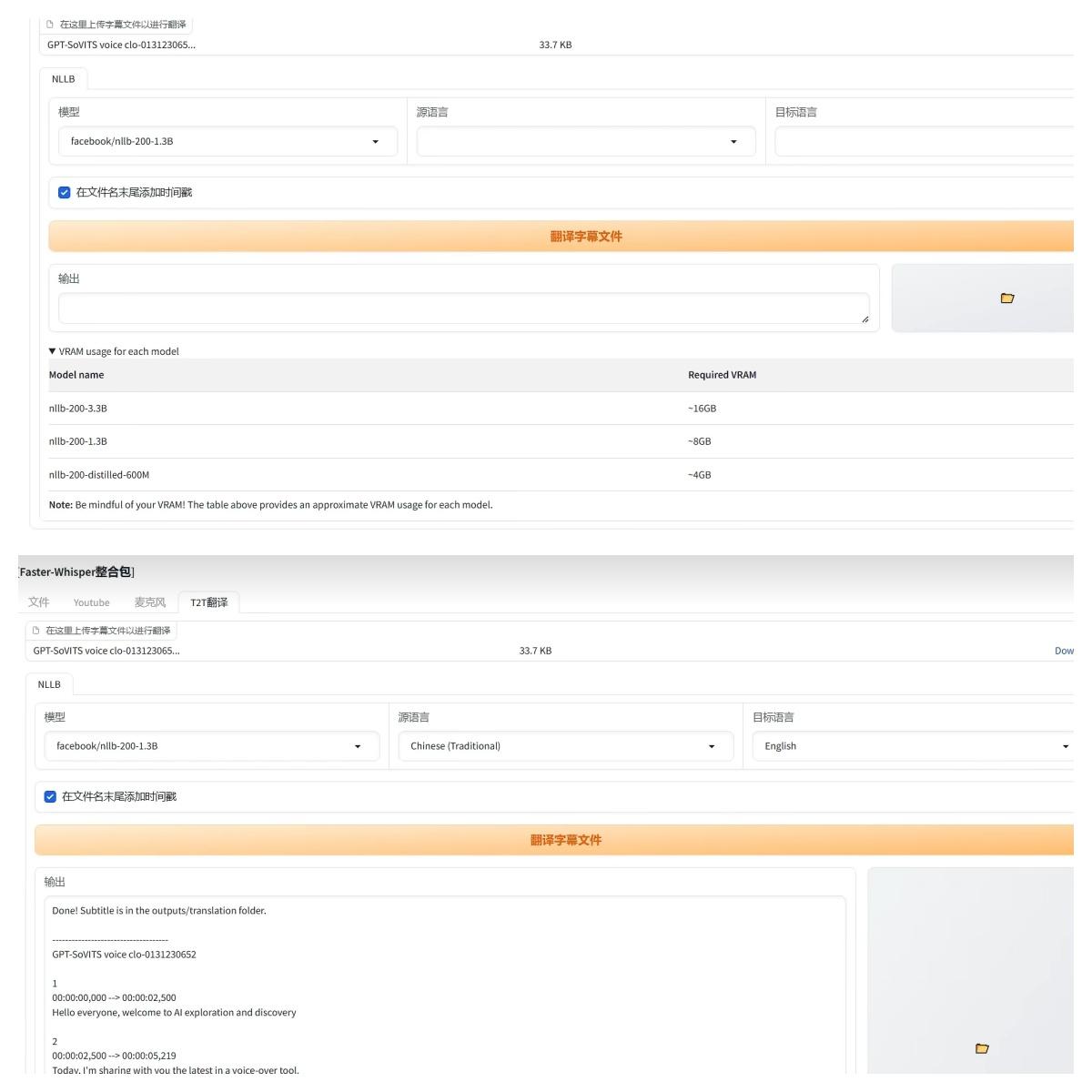
第三個功能:字幕翻譯。首先上傳一個字幕檔,就用剛才提取的字幕。然後選擇翻譯模型。這裡提醒一下,整合包裡只有1.3B的模型,如果選擇其他模型是需要線上下載的。不同參數的模型,在下面可以看到詳細的記憶體要求。最大的3.3B需要16G記憶體,推薦就用1.3B。然後選擇字幕的語言,再選擇翻譯後的目的語言,然後點擊翻譯。這份字幕大約5000多字,差不多4分鐘就翻譯完了。翻譯後的檔保存在“Translations”目錄裡。
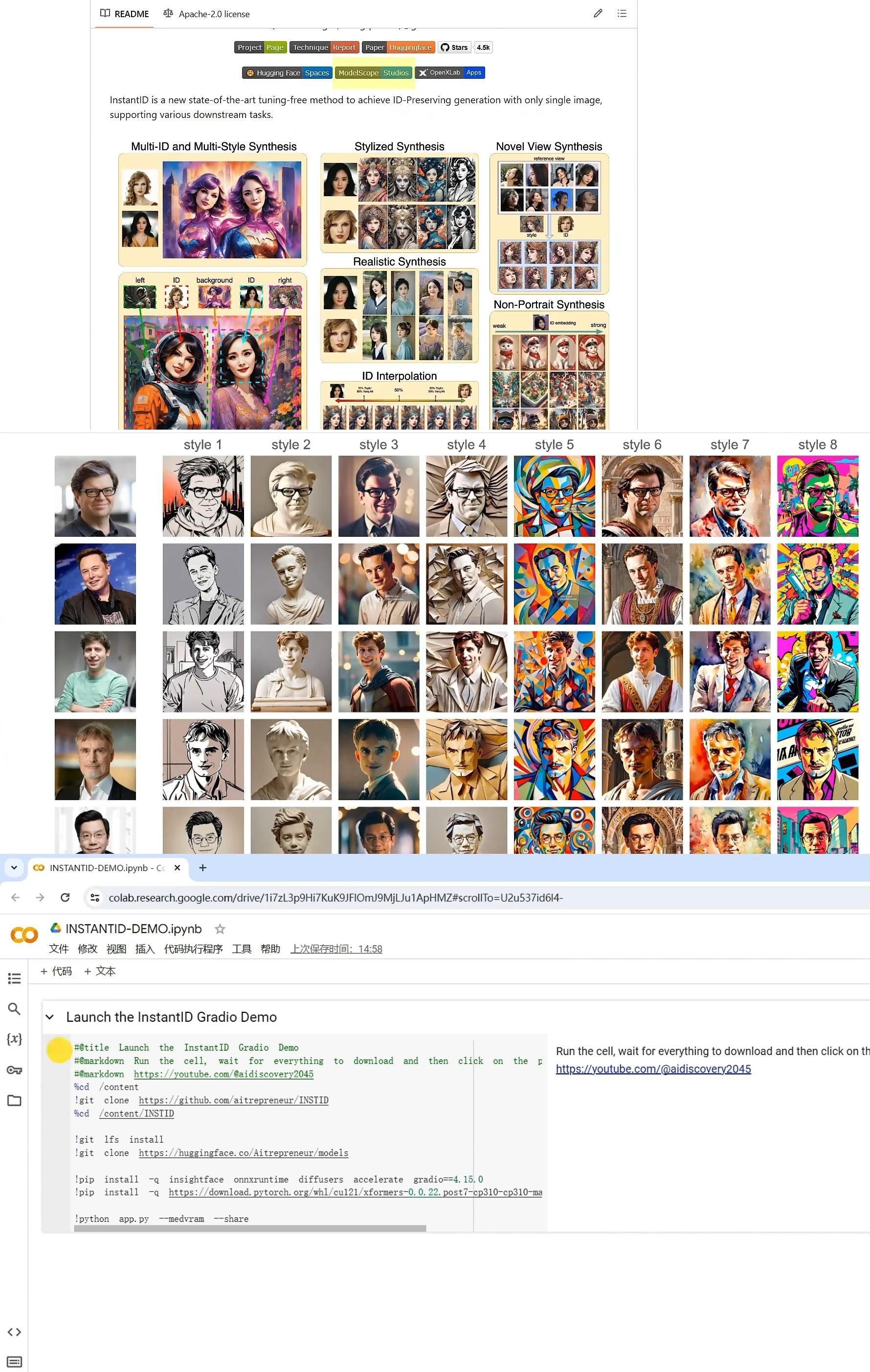
今天最後分享的最後一個AI工具是小紅書開源的“Instant ID”,只需要一張自拍,就能生成全套風格的寫真。與之前的“face chain”相比,它需要提供的照片更少,並且不依賴模型訓練,就能保證人物面部特徵高度相似。可以點擊這裡使用官方的演示網站免費體驗,不過人多的時候需要排隊。如果你有16G以上的NVIDIA顯卡,也可以使用整合包直接運行。在本地按兩下“一鍵啟動”,第一次運行需要線上更新一些模型。這裡的更新在中國大陸的話,會使用鏡像網站,不需要開VPN,耐心等待。下載完成後,就會自動打開網頁介面。電腦配置達不到要求的,也可以使用Colab來體驗。免費帳號就可以選擇T4顯卡,就能跑了。Colab腳本也是一鍵安裝的,點擊這裡的“執行”按鈕,等待下載、安裝完成。再點擊出來連結,就可以打開操作介面了。
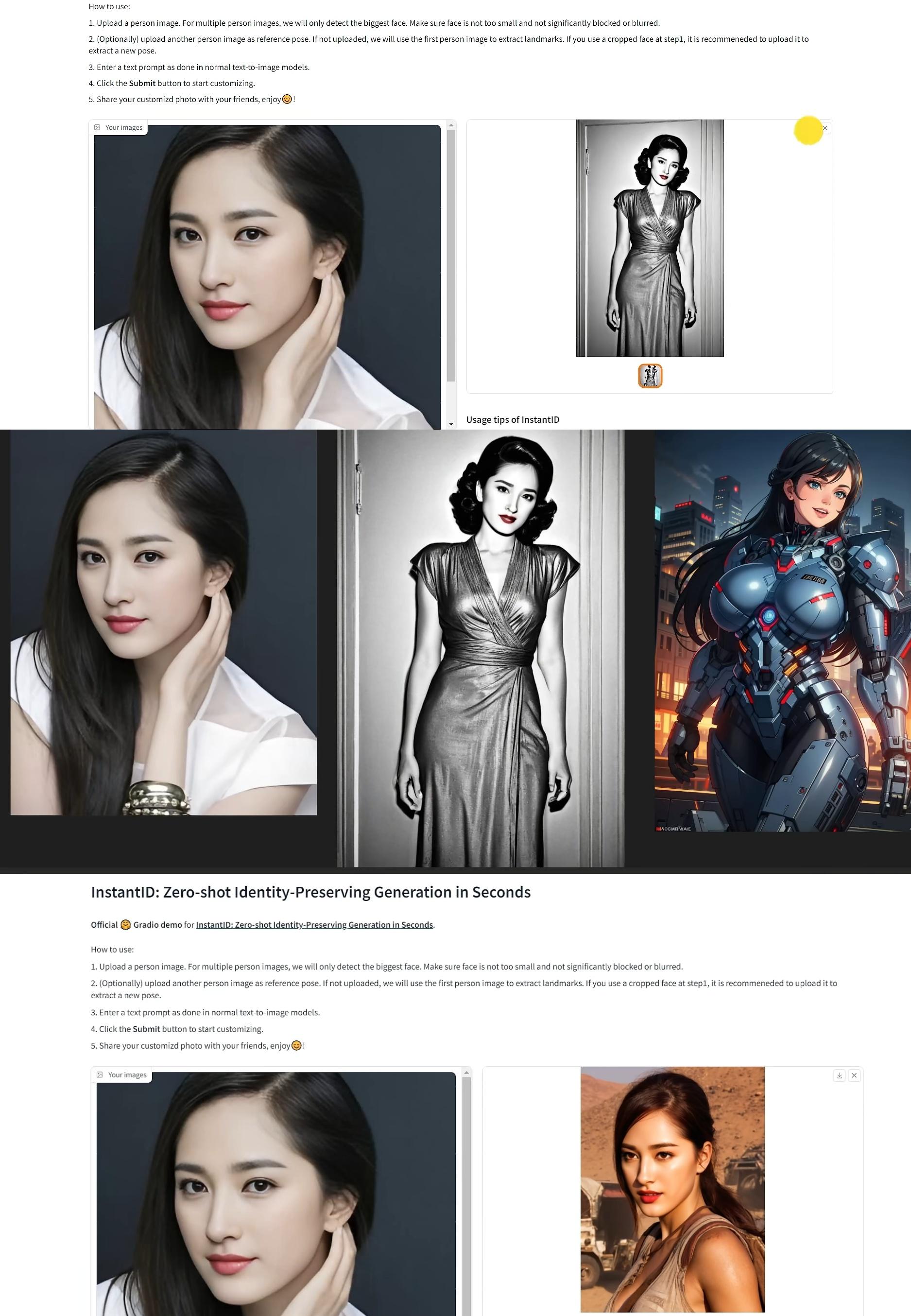
首先上傳一張照片,下面可以再給一張參考照片(參考照片不是必須的),我就隨便選一張。生成圖片提示這裡不需要複雜的描述,簡單一個單詞就可以了。主要是下面的選擇風格,不同風格對應不同的寫真效果。風格選好以後,下面的參數全部預設就可以了。然後點擊“提交”,出圖大概在40秒左右生成完成。可以來看一下,一張黑白電影風格的全身照,人物面部保真還可以。雖然給他的是一張半身照,但因為添加了一張參考圖片,最後生成的圖片尺寸還是全身的,包括人物姿態,也跟參考圖片有一些相似的元素。如果不使用參考圖,生成的圖片就完全保持了原圖的尺寸和面部特徵。其他元素,比如背景和畫風,這些主要取決於所選的風格。目前預知的風格類型有20多種,還在不斷的更新中。使用不同的風格,再加上參考圖片進行組合,可能會有意想不到的寫真效果。
好了,今天分享的6個工具就到這裡了。如果無法找到這些工具下載連結請私訊我哦,感謝大家支持,下期見。


相關文章












