我知道這一天早晚會來,但是沒有想到來的這麼快。大家好我是Wayne,這幾天我研究了一下Open AI,也就是美國開放人工智慧研究中心推出的最新產品Sora。說實話,相當震撼!震撼之處,不在於它能夠生成真假難辨的、超逼真的畫面,而在於它的畫面在很大程度上能夠重現物理過程。比如人在紙上畫畫會留下墨蹟,比如人吃一口漢堡會有咬痕。這個是不是說明AI已經在視覺層面開始理解世界了呢?
先說下Sora能做什麼。它是目前唯一可以實現一分鐘長度影片生成的AI大模型產品。其他的比如說Runaway Pica等呢,只能生成幾秒鐘的這種影片。而且Sora在影片解析度層面的直接上升到了1920*1080或者1080*1920,畫面比例可以任意調整,這在影片生成領域絕對是核彈級的表現。這個意味著,當Open AI的對手還在研究火銃的時候,它直接給了你一門火炮。它不但可以根據文字提示來生成相應的影片,還可以將一副靜態圖片變成動態影片,甚至可以將一個影片進行向前或向後的擴充。

如果你給他一個既有的影片,他可以任意更換影片中的各種元素。比如說這個跑車跑山路的影片,他可以把背景改為叢林,也可以改到1920年代,甚至可以將其改成水下場景。同時,你還可以將兩個毫無關聯性的影片,通過Sora增加一段中間的銜接,讓其自然過渡。比如無人機變蝴蝶在海底游泳,比如越野車與奔跑的豹子,比如淘金熱時期過渡到一個漂浮著鯊魚的現代都市。大家可以仔細觀察,中間的過渡,非常的流暢。

當然,作為一個影片生成工具,Sora完全可以生成一個靜態圖片,解析度呢,可以達到2048*2048。而前面講的這些,都是基本技能。而令Open AI都感到意外的是,在進行大規模訓練之後,Sora湧現出了一些令人驚歎的能力,比如3D連續型。大家看這個影片,鏡頭從高空降落,跟隨一對情侶往前走。再比如說這個山谷環繞,然後鏡頭鎖定在兩個登山者上。這兩組鏡頭有什麼特別之處呢?那就是無論鏡頭怎麼運動,它所描繪的這個三維場景中的物體,是連續存在或者運動的,這個就是3D連續性。

而這個還只是開始,長距離關聯和物體永存性,就更令人咋舌。比如說這個畫面,前景的遊客走過,在短時間內擋住了斑點狗。但是呢,狗是一直趴在窗戶上,這個是長距離關聯性的體現。再看這個,他是在一個樣品中,生成了多個視角的鏡頭,但是這個機器人是一直存在的,這個就是物體永存性的體現。而最炸裂的,還是世界交互型。這個影片中,有人在畫一棵樹,那麼大家可以看到,他畫過的地方,會有墨蹟,而不會消失。這個人在吃漢堡,吃完一口漢,堡明顯有缺失的一塊。而除了現實世界以外,Sora還能夠生成遊戲畫面,比如說我的世界。剛才說的這些能力呢,從人類視角來看,是不足為奇的。但是你要知道,對於AI來說,是相當神奇的一種表現。這意味著AI不僅可以創造出單幀的、具有合理的透視效果、光影效果和物體細節的畫面,它還可以把連續幀的畫面串聯起來,形成前後的高度關聯性和記憶特性。因為這種影片中每一幀畫面,他都是單獨計算出來的。那麼要保證單幀畫面中所有的組成元素在空間上的關聯性,同時保證連續幀,也就是影片畫面中所有組成元素在時間上的關聯性,是一個非常大的挑戰。

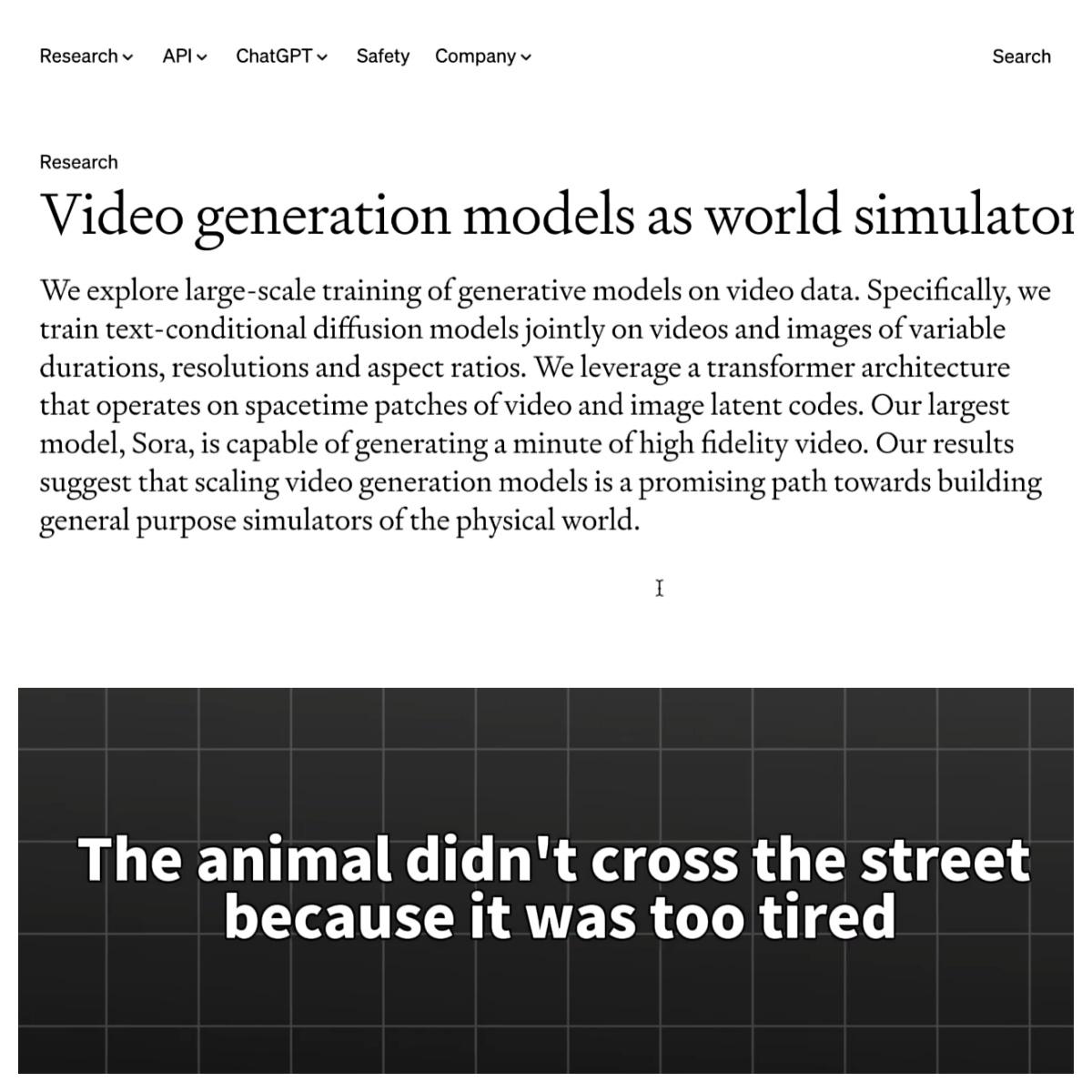
那麼,OpenAI具體是怎麼實現的呢?通過官方的technical report可以洞察一二。可以確定的是,Sora採用了一個diffusion Transformer這樣的混合模型,也就是以Transformer為基幹的一個diffusion架構。那麼這是什麼意思呢?diffusion這個模型它擅長的是圖片生成,而Transformer,也就是GPT BERT等大圓模型的合金技術,它所產生的是長序列的上下文關聯。Sora將這兩種技術融合在一起,構成了一個影片版的ChatGPT。當然呢,這個混合架構並不是OpenAI提出的,實際上,谷歌的魯米爾也是同樣的設計。那麼,為了方便理解呢,我們先簡單的說一下Transformer。Transformer的核心呢,也就是self attention,也就是這個自注意力機制。那麼在處理文本時呢,一個句子會先被進行分詞,形成一個個的TOKEN。然後每一個TOKEN會被向量化,那麼這個過程叫做Embedding嵌入。所謂的向量化,就是把這個TOKEN給轉換成一個多維的數字序列。那麼它在數學空間中,是佔據特定位置的。那麼與意相近,或者關聯性強的這個TOKEN呢,在空間中的位置就會比較接近。其實這個過程呢,就是給句子中的每一個元素一個數位示範。然後呢,所謂的self attention,就是讓每一個TOKEN的嵌入向量分別乘以三組權重矩陣,那麼得到QKV三組向量。q是query查詢,k是key鍵,v是Value值。那麼得到三組數以後呢,模型就會把每個q向量與所有的k向量做點積運算,得到一個注意力分數。那麼這個分數代表的是當前這個TOKEN與序列中其他元素的相關性,點擊越大關聯度越高。然後呢,把這個注意力分數通過Softmax函數轉換成一個總和為一的概率分佈。最後再把這個概率分佈與每一個TOKEN的微向量進行加權求和。那麼,由此得出的一個結果就是,每一個TOKEN都知道它與其他TOKEN之間的這個關係。這種機制解決的問題就是捕獲了一個文本序列中的長距離依賴關係。比如說在這句話中,“the animal didn't cross the street because it was too tired”,那麼通過注意力計算,機器就可以認知到,這句話中的“it”指的是“animal”,而不是“street”。而在一個Transformer模型中呢,一般會有多頭注意力機制。每一個頭都會關注不同的邏輯。那麼在剛才這句話中呢,一個頭可能會負責分析語法特徵,比如說“animal”和“cross”之間的關係;另外一個頭可以注意詞序的控制,比如說“the”後面是“animal”。那麼再一個頭呢,可能會負責將“animal”與“it”關聯在一起。那麼通過這種機制呢,大模型可以認知到一個文本中的長距離的這種依賴關係。而diffusion這個模型呢,是一個繪圖模型。那麼,很多人熟知的stable diffusion和MID journey呢,採用的就是這個模型。
Diffusion這個概念呢,是來源於物理中的擴散過程。比如說,一滴墨水滴到水中,從低熵到高熵。而機器要學習的,就是如何從高熵繁衍到低熵的狀態。那麼在訓練階段呢,系統會把一個原始圖片逐步添加雜訊,讓機器去學習這個圖片被雜訊污染的過程。然後呢,讓他學習如何去逆轉這個雜訊,恢復出原始資料來。那麼這樣,機器就學到了大量的逆轉經驗。那麼在推理階段呢,就會給到機器一個隨機的造成圖,讓他基於過去學習的這個逆轉過程,來恢復出一個特定的圖像。而具體是什麼圖像呢,就依賴于文本提示的指引。所以在Sora這個產品中呢,你可以認為diffusion這一部分呢,是負責繪圖。那麼Transformer這一部分呢,就是負責指導繪圖。然而,這裡Transformer需要處理的是影片資料,那麼所以系統會先把影片給切塊兒,也就是把每一幀畫面給拆分成patch。那麼這個patch呢,就相當於是前面的文本Transformer需要處理的每一個TOKEN。很顯然,每一個patch也會被壓縮成數字序列,用於後續的注意力計算。那麼只不過這個地方呢,它需要計算的是空間注意力和時間注意力。還記得前面我們說過的,這個創作方面的能力,就是捕獲長距離依賴關係。那麼這個能力在影片領域,就是發現單幀畫面中各個元素的空間慣練性,以及連續幀的畫面中各個元素的時間慣練性。也正是因為Sora採用了patch這樣的概念,那麼從而可以讓它生成的圖片擁有相對自由的比例和解析度。因為每一個影片,都可以看作是三維層面的一堆patch的疊加。

當你給Sora輸入一個文字提示的時候,他有一個專門的演算法來豐富你的描述。然後呢,基於這一個豐富後的描述,Sora就會結合depoted和track form各自在這個畫面推演和時空連續性方面的能力,來創建一個動態的、看上去合理的畫面。當然呢,我們所說的這個,只是一個基本的概念性的原理。那麼oPen AI呢,它也並沒有披露它具體的實踐方法,還有更多的這種專業的技術細節,也並非我們這種業餘愛好者能夠洞察到的。那麼我們這個講解呢,僅供參考,一切以權威的AI專家講解為准。實際上,並不是說你做到了這樣的架構設計,就能夠立刻收穫驚豔的效果。那麼這裡面依賴一個“事”,那就是大力出奇跡。Sora不僅需要海量的影片訓練素材,也需要很大的算力。那麼這個是最基礎的計算效果,非常的恐怖。那麼這個是在其基礎上增加了4倍計算的一個效果,那麼能夠看出來這原來是一隻小狗,而且它有了比較清晰的動作,但是好像不是很協調。而在32倍計算後呢,就得到了一個畫面清晰、沒有殘影、而且動作神態非常自然的效果。大家注意,這只狗的爪子在踩到雪和草的時候呢,都有相應的效果出現。那麼可以說,對於真實世界的這種物理還原,還是挺細緻的。

但是open AI呢,也給出了很多失敗的場景。比如說這個杯子漏水的場景,就非常奇怪。再比如說這個方向錯了,那麼這個上演了分身術。這個神奇的椅子,那麼再看這個影片就更加詭異了。老人吹蠟燭,不僅沒有沖准,而且這個蠟燭呢也沒有熄滅。後面的人物的這個手部動作,也相當詭異。其實在這個影片中呢,也有很大問題,那就是這只狗在現實中應該沒法像影片中這樣跨越這個窗臺。但是至少從open AI放出的大部分影片來說的話,整體效果是非常出彩的。那麼最後的問題在於,它到底是在操控2D層面的圖元,還是成為了一個3D層面的物理引擎呢?其實兩個說法都有一定道理。因為你給到Sora的訓練資料呢,確實只是2D的這種平面內容,是不存在深度資訊的。所以它整個的計算都是發生在一個二維空間內的,只不過把這個二維圖元,轉化為了一個數學表達進行計算,再映射為圖元空間。所以你說它是2D層面的一個圖元操控說法,其實是也有道理的。

但其實呢,我比較傾向於它是一個3D的物理引擎這個說法。因為Sora很有可能呢,已經建立了對於透視的理解,這就意味著即便他在操控圖元,那麼他也能夠讀懂畫面中看上去平面的物體,他實則是有一定的深度資訊的。而這個深度資訊,是通過訓練過程以隱式的變數存在的。也就是說,我們並沒有人為添加顯示的物理參數來引導它。但是呢,它在訓練過程中自動的獲取了一些物理參數,從而呢可能具備對於3D的理解能力。目前我們看到的一些奇怪的畫面,實際上呢,可能是因為訓練不到位導致的。那麼,隨著訓練素材的增加和參數的積累,Sora對於其真實的物理過程的這種理解呢,也會更加的到位。因為他生成的畫面,都是基於他看過的畫面。理論上來說,如果你讓他看1,000萬個杯子傾倒的鏡頭,他也可能會完美呈現一個相同的過程。因為他會提取到杯子在倒下時的這個特徵規律,比如說液體不可能先於杯子傾倒而出現在桌面上,那麼這些都是可以訓練出來的。那麼假設訓練資料足夠龐大,那麼參數在翻幾倍,算力繼續提升的話,那麼Sora完全有可能會模擬出大部分現實世界中的物理交互過程。所以相比虛幻5這樣的遊戲引擎,靠大量的專門演算法來精確控制每一個圖元的輸出,Sora的方式可能更加接近真實世界的物理規律。當然,這也需要我們進一步去驗證和探索。Sora可能更像是一個現實世界的物理引擎,只不過後者呢,是靠這個大模型基於大量的這個資料得來的經驗來驅動的。
如果Sora只是單純的一個2D圖元操控系法的話,那麼將一些計算得出的概率映射成一個畫面,那麼它不可能會湧現出前面所提到的一些時空連續性方面的能力,能帶入時空觀,並且遵循一些基本的物理邏輯,說明機器是具備對現實世界的一定的理解能力的。那麼關於這個問題,你是怎麼看的呢?歡迎討論留言,感謝收看。


相關文章












